
Continuous Delivery at Github

Si il existe une des équipes DevOps qui assurent grave, c'est probablement chez Github. Alain Hélaïli partage son expérience dans un talk disponible sur infoq.com que je recommande :
https://www.infoq.com/fr/presentations/continuous-delivery-github-alain-helaili
Et parce que j'ai souvent besoin de m'y référer pour illustrer des propos, je profite de cet espace pour y inscrire mon TL;DR qui sera forcément un peu biaisé par rapport à l'original:
Concernant les moyens de communication dans une entreprise qui voit ses salariés largement distribués :
Chez github on a arrêté de s'envoyer des emails. le marketing a son repo et ouvre une issue pour dialoguer
[…]
Communication uniquement par écrit : si une discussion n'a pas d'url, on estime qu'elle n'a jamais eu lieu
Le workflow de développement :
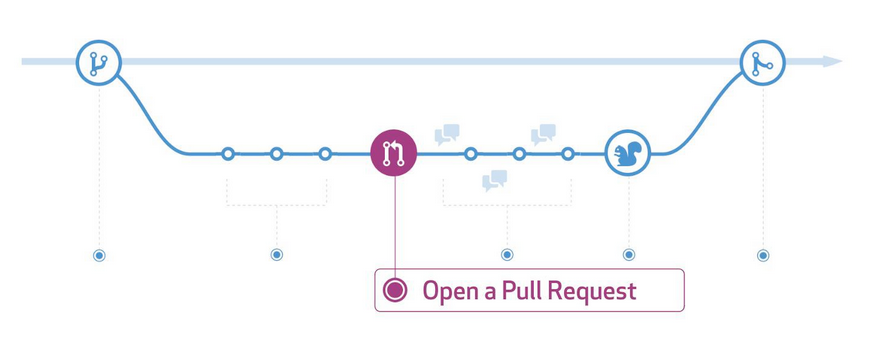
On encourage à ouvrir la PR le plus tôt possible, avant l'implémentation. Car ça ouvre la discussion et permet la synchronisation des membres. Une fois qu'on implémente, on va pouvoir utiliser la PR pour faire du code review.
Plusieurs tâche travis pour avoir des informations précises sur ce qui est remonté. Par exemple une tâche pour le lint. L'information est prémachée, pas besoin que le développeur aille chercher pourquoi le code n'est pas passé dans la CI. Sachant que certains check sont obligatoires, d'autres optionnels…

Un développeur crée une feature branch, rajoute des commits, ouvre très tôt une PR, discute du code, puis très rapidement, il livre (le petit écureuil)
On utilise hubot connecté à notre chat à qui on peut envoyer des commandes. Mais aussi il voit ce qui se discute dans le chat et ouvre des issues et des PR dans github. Mais son premier job est de permettre d'assister le déploiement :

Et depuis le chat, on peut lancer une commande de déploiement. Il n'y a que ça à faire pour envoyer du code en production (un développement n'est terminé que s'il est déployé et fonctionne en production). Le développeur qui vient de déployer a alors accès en tant que responsable à ce qu'il se passe en prod afin de voir si son code n'a pas tout cassé (outil haystack).

Lorsqu'il y a un problème, c'est hubot qui gère : il ouvre l'issue avec les logs, etc. Tout est centralisé grâce à hubot.
[…]
Et si tout s'est bien passé sur la prod, alors on peut merger la feature-branch dans master. Si jamais la feature branch a planté la prod, on redéploie master : la seule base stable et validée.
On n'utilise pas le
successful git branching model: c'est trop compliqué. On n'a pas de QA, pas de notion de sprint, pas vraiment de notion de release. Trop de manipulations à faire avec lesuccessful git branching model.
Les gens veulent des sprints, mais des MEP tous les 3 mois. Alors que nous on ship la feature branch en prod, mais on rollback en quelques secondes si y'a un souci. Si tout va bien, on merge dans master. C'est pas parce que c'est en prod que le client final le voit. On fait la QA sur ce qui est déjà en prod.
Exemple de prod en vrac : ça a duré 25 minutes, 3500 exception à la seconde

A/B testing avec github/scientist (300 expérimentations en prod en parallèle), feature flipping avec jnunemake/flipper. On a la feature sur la prod, on peut l'ouvrir au public sans refaire un déploiement. Je peux deployer un mardi et donner la fonctionnalité à l'utilisateur le vendredi d'après. (+ outils d'évolution des DB MySQL https://github.com/github/gh-ost)
Voilà, je redonne les références du talk Continuous Delivery at Github par Alain Hélaïli.


